k8s编程-介绍
0x00 什么是kubernetes编程
kubernetes编程在这个里面指的是开发一个k8s原生应用程序,通过直接和k8sAPI交互,查询/更改resource的状态.
0x01 扩展模式
k8s是一个非常强大,并且内部也是非常容易扩展的系统.通常情况下有多种方法可以定制或者扩展kubernetes:可以定制自己的控制组件(类似kubelet, kubeapiserver)通过kubeConfig,flags(需要一个client来连接到k8s集群,然而创建一个客户端一般通过kubeConfig配置文件或者指定apiserver来创建,也可以使用incluster模式)
一般由以下几种扩展模式
- 云厂商提供Cloud Manager来对接云平台
- kubelet 插件
- kubectl 插件
- api扩展(webhook)
- CustomResource(crd, 可以通过operator-sdk, kubebuilder,code-generator等方式来创建一个operator)
- CustomApiServer
- Scheduler Extension
0x02 Controller & Operator
在k8s术语里面,controller实现了一个控制循环流:通过apiserver来监控k8s集群里面的资源,不断的做一些事情,来是的资源的spec和status保持一直.(controller就是一个无限循环的二进制可执行程序,伪代码如下:)
1 | for { |
控制流如下:
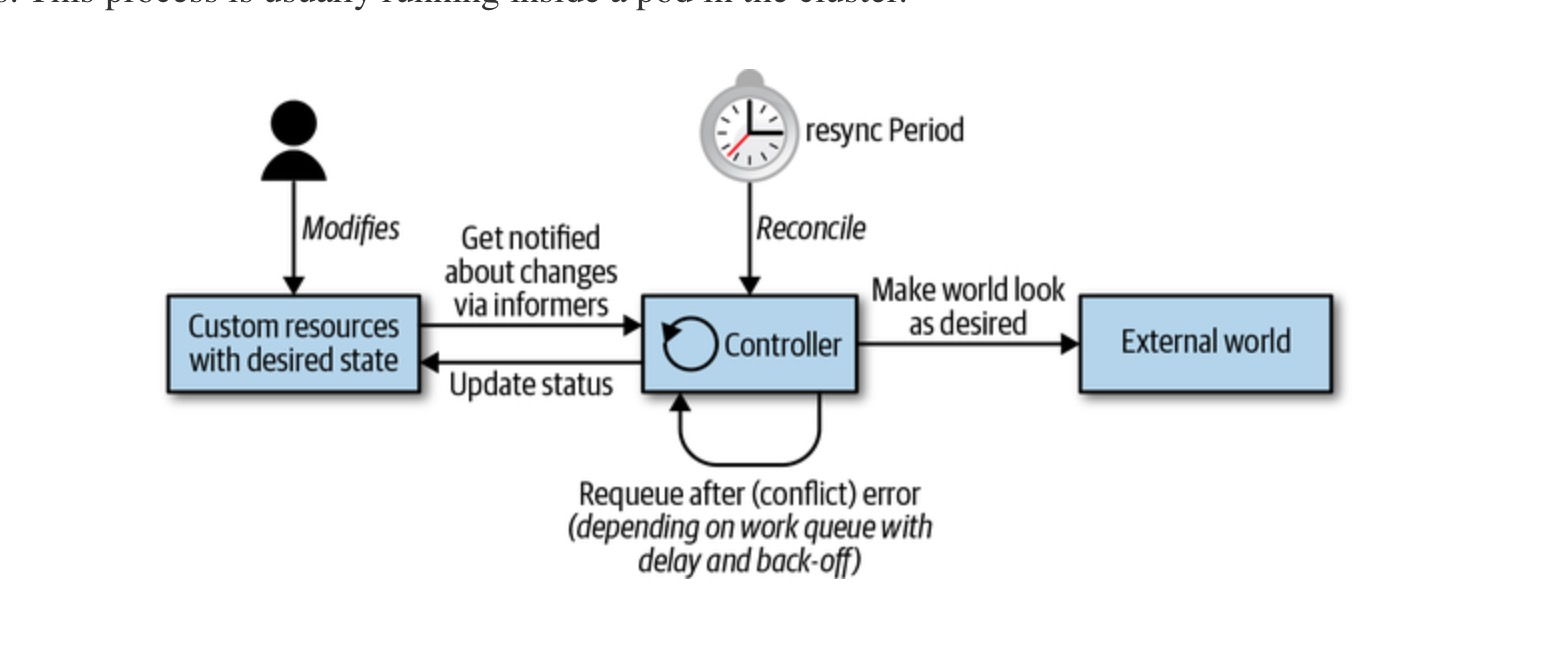
当这个资源可以是k8s标准资源(pod,configmap, deployment….)也可以是用户自定义的资源(mysqlCluster, hahaCluster)
文字描述如下:(这里增加描述会在乐观并发讨论那会用到,记住这里逻辑)
- step1: 读取资源的状态
- step2: 改变object的状态
- step3: 将更新后的object通过API存储到ectd 里面
- step4: 重新执行step1
controller里面两个重要的组件: Informer和WorkQueue
Informer主要是监控k8s的资源,当这些资源的状态发生改变的时候,会把这些event发送给workqueue,在分发给具体的worker来处理workqueue由于一个k8s集群里面会有很多controller,用户没有办法区分哪个event是属于哪个controller的,因此就需要自己实现一个自己的workqueue,来存储自己关心的哪些数据。
0x03 Event
在k8s内部大量的使用event,并且组件与组件之间也是低耦合的(有一篇文章评价event是k8s的DNA, 组件之间通过也通过event来触发)。一般的分布式操作系统里面可能使用RPC方式来通信,但是k8s 不是。k8s controllers 通过APIserver来监控资源的curd,当有event发生的时候会触发一些逻辑.
从event角度来看, k8s 本身就是一个event的queue,kubectl/kubescheduler/controller..既是event的消费者也是event的生产着。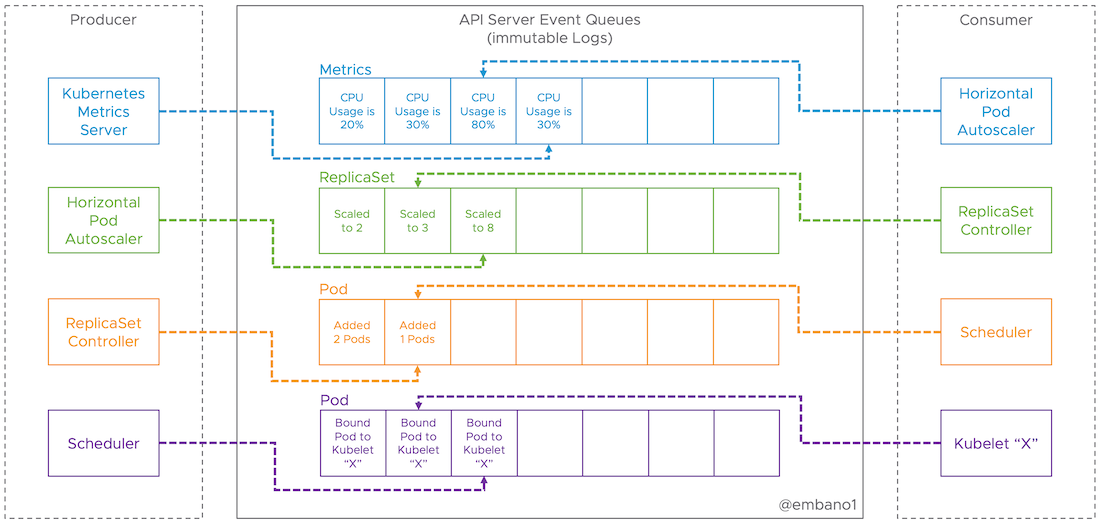
0x03边缘触发和水平触发
通过检查状态有两种选择:1.边缘驱动触发 2.水平驱动触发
- 边缘驱动触发: 在这种模型下,当有一个状态发生改变的时候,一个handler就会被触发
- 水平驱动触发: 在这种模型下,会定期的扫描所有的状态,当有状态发生改变的时候,会触发一个handler。
很显然后一种采用了轮训的方式,这种模式扩展性不是很好,它的延迟取决于有多少object需要扫描和APIserver的响应速度. 在k8s里面有多个异步controller同时被调用,那么将会耗费大量的时间才能满足用户的期望.
前一个选择就高效的多了。这个延迟主要取决于controller能够处理的有多快,因此k8s主要采用了event驱动模型(边缘触发)
在k8s里面,有很多组件会改变资源的对象,每一个都会产生一个event,这些组件就称为”event resources”或者”event producers”。另一方面在controller里面我们只关心如何以及何时消费这些event。
在分布式系统里面可能有很多组件并行的执行,这些event就很有可能是无序的异步接进来。当我们组件如果不够好就有可能出现很多问题,下面讨论几种不同的策略所带来的影响:
- 边缘触发(only)
- 边缘触发机制,水平触发的逻辑(每次仅仅处理最新的那个event,也就意味着它需要对所有的event做个对比,然而这是水平触发的逻辑)
- 边缘触发机制,带有额外同步的水平触发逻辑
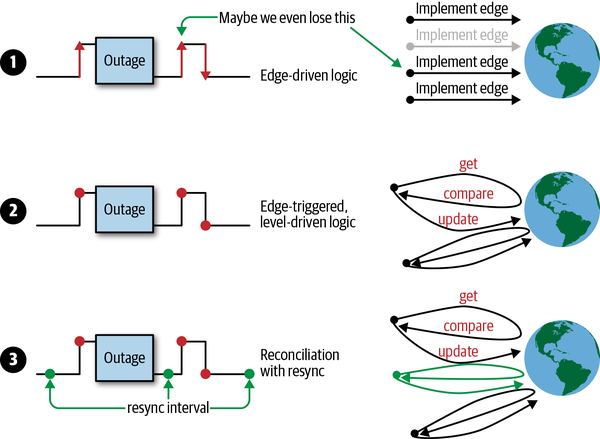
- 边缘触发: 这种很容易造成event的丢失,当网络问题,或者controller自身的bug导致的。假设一个replicacontroller,当pod 终止了时候需要替换这些终止的pod, 但是当event丢失的时候,这就意味着relica 无法感知到pod 丢失了,这个replica将会以比较少的pod在运行。
- 第一种带来的问题第二种策略基本可以修复,因为它是基于水平触发的逻辑(获取当前最新的event,当发现spec.replica和status.replica不一致的时候会做一些改变),但是这种也有问题,但是这种也存在这一些问题,当丢失了event的时候,它会一直和当前正在运行的pod做对比,直到下一次有一个podupdate的时候,它才会把所有的丢失的pod给弥补起来.
- 第三种增加了持续同步机制(默认5分钟),如果没有新的pod 进来,它会每5分钟重新reconcile一次,即使app运行的非常稳定,也没大量的event产生。
0x04 乐观并发
在controller流程那讨论到的几个流程,在step2 在改变一个object状态的时候,其他的controller也改变这个object的状态就会导致错乱。在分布式系统里面这个controller可能只是众多需要更改这个object对象的controllers 里面的一个,并发的写就可能因为写冲突导致失败。
先简单看下分布式系统里面调度情况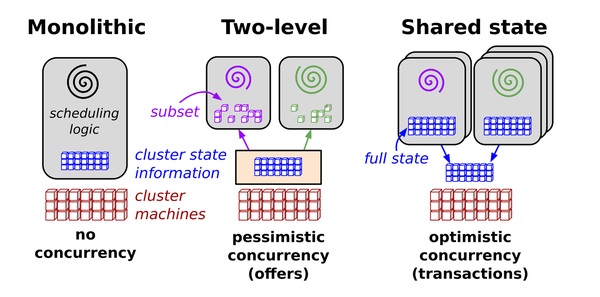
解决方案是基于共享状态构建的一种新型调度框架,使用无锁乐观并发控制来实现可扩展性和伸缩的可能性。这个框架被用到了Omega调度框架里面
k8s也继承了brog许多设计理念,借鉴了omega的事物控制平台机制,为了在没有锁的情况下实现并发控制,k8sapiserver采用了乐观并发机制, 这就意味着当k8s APIserver在接受到并发写的请求的时候,他会拒绝两次写请求的后面一个请求。由客户端来处理这个冲突(客户端可能是kubectl,controller,scheduler。。。。)
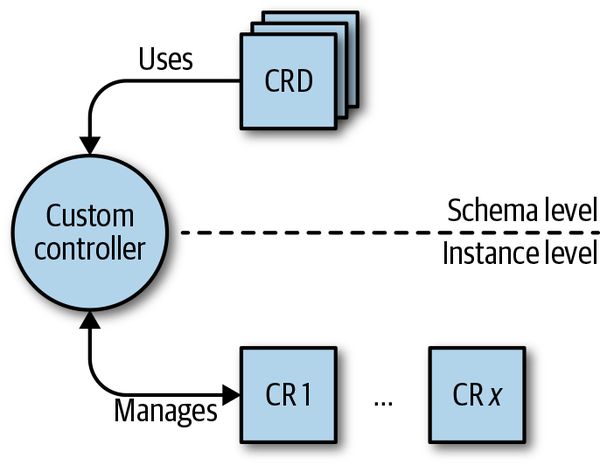
0x05 Operator
在k8s里面operator一般理解为两部分
- crd, 用户自定义的资源描述
- custome controller
0x04 参考
《programming kubernetes》